
What generation of AI are you selling?
Before signing a product contract, ask the basic question: Are we buying cutting-edge AI or a fossil from Chapter 1 of the machine learning history book?

Over the past decade, the U.S. school security tech market has grown from a niche industry into a multi-billion-dollar juggernaut fueled by lobbying for government funding and stoking fear of school shootings. Many school districts are being pitched AI-powered security technology, but few educators or board members fully understand what generation of AI they’re being sold.
Some school security tech companies still rely on outdated, first- or second-generation models that are narrow systems trained on limited labeled data that require constant human oversight to catch errors. These older systems don’t scale well, especially in dynamic environments like schools, where false alarms and missed threats can have serious consequences.

Here’s a clip from the July 11, 2025 episode of the All In podcast discussing the difference between using labeled human data versus giving vast amounts of data to unsupervised, self-improving models like GROK 4 (highest performing LLM on the 2,500 question Humanity’s Last Exam):
In contrast to the old standalone classifier models, today’s sixth-generation general-purpose AI models (like ChatGPT-4o and GROK 4) are trained on trillions of data points using self-supervised learning and can handle a broad range of tasks with far greater adaptability and accuracy than a special purpose model.
If a school district signs a multi-year contract with a company using outdated tech, they risk getting stuck with expensive, error-prone systems in a rapidly evolving AI landscape.
Early Image Classification
Back in the 2010s, early AI systems relied heavily on human-labeled training data. If you wanted an early AI model to identify cats in photos, you had to manually label 25k of images as "cat" to train the model. To classify multiple types of animals, datasets ballooned to 14 million human-labeled images. More labeled data improved accuracy but labeling is slow and expensive, making it impossible to build a perfectly accurate system at scale.

A brute-force workaround was the "human-in-the-loop" model, where people manually reviewed and corrected errors. For example, if a system is 95% accurate and processes 100,000 images an hour, a human reviewer must correct about 83 mistakes per minute. Just like labeled training data, human review becomes an unstainable, exponential labor problem.

This is why older, special-purpose AI classifiers aren’t viable at scale. Today’s general-purpose models (large language models) are roughly sixth-generation compared to those early 2010s systems. They're trained on trillions of pieces of unlabeled data using self-supervised learning and can adapt to a wide range of tasks without needing to be retrained for each one. That’s why the newest LLMs perform well even on problems they weren’t even designed to solve.
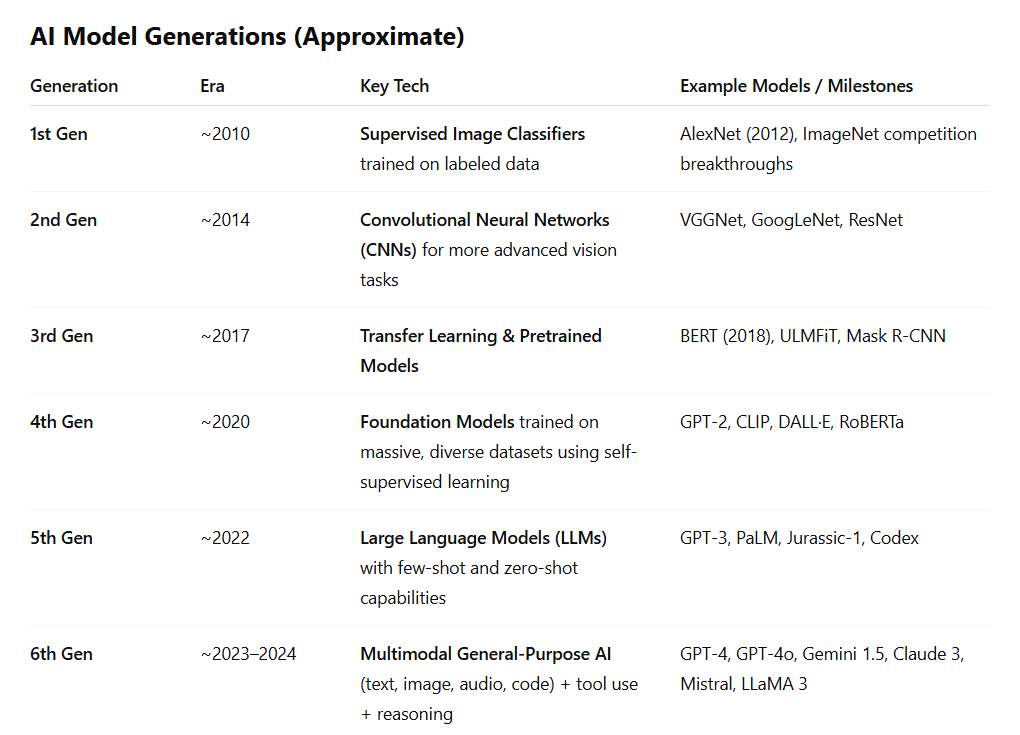
Before signing a security tech contract, school leaders should ask a basic question: Are we buying cutting-edge AI or a fossil from Chapter 1 of the machine learning history book?
David Riedman is a Ph.D.c. in Artificial Intelligence studying the performance of LLM compared to human experts. Using human intelligence, he founded of the K-12 School Shooting Database, an open-source research project that documents gun violence at schools back to 1966. He hosts the weekly Back to School Shootings podcast and writes School Shooting Data Analysis & Reports on Substack.